





Algorithm erklärt: what is an algorithm, Greedy Algorithm & Dijkstra Algorithm – verständlich, praxisnah, prüfbar
Algorithm erklärt: Du hörst das Wort algorithm ständig: im Alltag (Empfehlungen, Navigation, Social Media), im Job (Datenanalyse, Automatisierung) und im Studium (Programmieren, Mathe, Informatik). Und trotzdem bleibt es für viele vage. Ist ein Algorithmus einfach „Code“? Ist es „KI“? Oder nur eine „Rechenregel“? Die Wahrheit ist: Ein Algorithmus ist etwas viel Grundlegenderes – eine klare, wiederholbare Vorgehensweise, die aus Eingaben Ausgaben macht. Wenn du diese Grundidee wirklich verstehst, wird plötzlich alles leichter: von der Frage what is an algorithm bis hin zu konkreten Klassikern wie dem dijkstra algorithm oder dem greedy algorithm.
Dieser Artikel ist so geschrieben, dass er zwei Dinge gleichzeitig leistet: Er erklärt Konzepte verständlich und liefert dir dennoch die Tiefe, die eine Autoritätsseite braucht. Du bekommst Praxisbilder, typische Fallstricke, Kriterien für „gute Algorithmen“, und ein sauberes mentales Modell, mit dem du neue Verfahren schneller einordnen kannst. Ganz wichtig: Wir vermeiden Schablonen-Text. Stattdessen lernst du, Algorithmen wie Werkzeuge zu sehen – mit passenden Einsatzgebieten, klaren Grenzen und nachvollziehbaren Entscheidungen.
What is an algorithm? Die beste Definition für Alltag und Technik
What is an algorithm lässt sich am saubersten so beantworten: Ein Algorithmus ist eine endliche Folge eindeutiger Schritte, die ein Problem löst oder eine Aufgabe ausführt. „Endlich“ bedeutet: Er endet, statt in einer Endlosschleife zu hängen. „Eindeutig“ bedeutet: Jeder Schritt ist so klar formuliert, dass er wiederholbar ist – unabhängig davon, ob ein Mensch oder ein Computer ihn ausführt. Und „Problem“ kann vieles sein: Sortieren, Suchen, Routen finden, Bilder komprimieren, Betrug erkennen oder ein optimales Portfolio berechnen.

Die praktische Konsequenz ist wichtig: Ein algorithm ist nicht automatisch „intelligent“ und nicht automatisch „KI“. Er ist eine strukturierte Vorgehensweise. KI-Modelle nutzen Algorithmen, um zu lernen und zu entscheiden – aber ein Algorithmus kann auch völlig ohne Datentraining funktionieren. Genau diese Trennung hilft, wenn du moderne Tech-Begriffe entwirren willst: Algorithmus ist die Methode, KI ist oft ein spezieller Anwendungsbereich mit statistischen Modellen.
Warum Algorithmus-Verständnis heute Macht ist
Algorithmen entscheiden, was du siehst, was dir empfohlen wird, wie Routen berechnet werden, welche Preise dynamisch entstehen und wie Ressourcen verteilt werden. Wer algorithm als „Black Box“ betrachtet, fühlt sich schnell ausgeliefert. Wer ihn als „Regelsystem“ versteht, kann Fragen stellen: Welche Eingaben fließen ein? Welche Ziele optimiert das System? Welche Nebenwirkungen entstehen? Diese Fragen sind nicht nur akademisch – sie sind digitaler Alltag.
Für Unternehmen ist algorithmisches Denken ebenfalls ein Wettbewerbsvorteil. Es geht nicht darum, jeden dijkstra algorithm auswendig zu können, sondern darum, Problemtypen zu erkennen: Ist das ein Pfadproblem? Ein Optimierungsproblem? Ein Ressourcenproblem? Sobald du das Muster siehst, kannst du passende Methoden wählen, statt planlos zu „programmieren, bis es irgendwie klappt“.
Algorithm vs. Programm vs. Heuristik: drei Begriffe, die oft verwechselt werden
Ein algorithm ist die Schrittfolge, ein Programm ist die konkrete Umsetzung in einer Sprache, und eine Heuristik ist eine „gute Daumenregel“, die oft funktioniert, aber keine Garantie liefert. Das ist nicht Haarspalterei: Wenn du im Team sagst „unser Algorithmus ist falsch“, kann das heißen, dass die Idee falsch ist – oder nur der Code, der sie implementiert. Wenn du sagst „wir nutzen eine Heuristik“, akzeptierst du bewusst, dass das Ergebnis nicht immer optimal ist, aber schnell oder praktisch genug.
Gerade beim greedy algorithm ist diese Unterscheidung entscheidend. Greedy-Verfahren wirken oft wie Heuristiken, sind aber in manchen Problemklassen tatsächlich optimal. Ein greedy algorithm ist also nicht automatisch „ungefähr“ oder „unscharf“ – er ist eine Strategie, die unter bestimmten Bedingungen mathematisch sauber optimal sein kann.
Die fünf Eigenschaften, die einen Algorithmus „gut“ machen
Ein guter algorithm ist korrekt, effizient, verständlich, robust und testbar. Korrekt heißt: Er liefert richtige Ergebnisse für alle zulässigen Eingaben. Effizient heißt: Er arbeitet in angemessener Zeit und nutzt Ressourcen sinnvoll. Verständlich heißt: Menschen können ihn warten, überprüfen und verbessern. Robust heißt: Er bricht nicht sofort bei Randfällen oder leicht veränderten Bedingungen. Testbar heißt: Du kannst ihn mit Beispielen, Invarianten oder formalen Eigenschaften validieren.
Diese Eigenschaften sind in der Praxis ein Balanceakt. Ein super-effizienter Algorithmus, den niemand versteht, ist in vielen Teams schlechter als ein leicht langsamer, aber gut wartbarer. Umgekehrt kann ein „zu einfacher“ Algorithmus in Produktionssystemen teuer werden, weil er skaliert nicht. Deshalb ist algorithmische Kompetenz heute nicht nur Mathematik, sondern auch Engineering-Urteilskraft.
Komplexität ohne Angst: Warum Big-O dein bester Freund ist
Big-O ist keine Zauberformel, sondern eine Sprache für Wachstum: Wie verändert sich Laufzeit, wenn die Eingabe größer wird? Ein algorithm mit O(n) wächst linear; O(n²) wächst quadratisch und wird bei großen Daten schnell teuer; O(log n) wächst sehr langsam und ist oft extrem gut skalierend. Du musst keine Beweise schreiben, um Big-O praktisch zu nutzen. Du brauchst nur Intuition: Welche Teile meines Verfahrens laufen „für jedes Element über alle anderen“? Das sind die typischen Quadratik-Fallen.
Gerade bei Pfadproblemen wie dem dijkstra algorithm ist Komplexität ein praktischer Faktor: Mit einer schlechten Datenstruktur kann derselbe Algorithmus deutlich langsamer sein. Mit einem guten Priority-Queue-Ansatz wird er effizienter. Das zeigt, warum „Algorithmus“ und „Datenstruktur“ zusammen gedacht werden müssen. Ein Algorithmus ist selten nur eine Idee; er ist eine Idee plus passende Strukturen.
Greedy Algorithm: Die Strategie in einem Satz, die du nie wieder vergisst
Ein greedy algorithm trifft in jedem Schritt die lokal beste Entscheidung in der Hoffnung, dass daraus global das beste Ergebnis entsteht. Das klingt riskant, ist aber in vielen wichtigen Fällen genau richtig. Der Trick ist nicht die Strategie an sich, sondern die Frage: Wann ist „lokal best“ auch „global best“? Wenn diese Bedingung erfüllt ist, bekommst du eine Lösung, die oft deutlich einfacher und schneller ist als komplexe Optimierung.
Ein Klassiker: Intervallplanung (z. B. möglichst viele nicht überlappende Termine auswählen). Greedy funktioniert optimal, wenn du immer das Intervall wählst, das am frühesten endet. Du triffst lokal eine kluge Wahl und bekommst global die beste Anzahl. Das ist ein perfektes Beispiel, weil es zeigt: Greedy ist nicht „faul“, sondern manchmal mathematisch elegant.
Wann Greedy scheitert: das Muster hinter den Gegenbeispielen
Greedy scheitert typischerweise, wenn frühe Entscheidungen spätere Möglichkeiten „blockieren“, die insgesamt besser wären. Das passiert, wenn lokale Optima nicht zu einem globalen Optimum zusammengesetzt werden können. Ein berühmter Kontext ist das „Rucksackproblem“ (Knapsack): Wenn du einfach das beste Verhältnis aus Wert und Gewicht nimmst, bekommst du oft nicht die optimale Kombination.
Der praktische Nutzen ist: Wenn du Greedy nutzt, solltest du immer eine Gegenbeispiel-Brille tragen. Frag dich: Kann eine frühe Wahl verhindern, dass später zwei gute Dinge zusammen passen? Wenn ja, dann brauchst du möglicherweise dynamische Programmierung, Backtracking oder einen anderen Ansatz. Greedy ist ein Werkzeug, kein Dogma.
Dijkstra Algorithm: Warum er in Navigation und Netzwerken so zentral ist
Der dijkstra algorithm ist ein Verfahren, um in einem Graphen die kürzesten Wege von einem Startknoten zu allen anderen Knoten zu finden – vorausgesetzt, alle Kanten haben nicht-negative Gewichte. In Alltagssprache: Wenn du ein Straßennetz (oder ein Netzwerk) hast und jede Verbindung eine „Kosten“-Zahl besitzt (Zeit, Entfernung, Risiko), dann findet Dijkstra zuverlässig die günstigste Route. Genau deshalb ist er so beliebt: Er ist verständlich, robust und in vielen realen Modellen anwendbar.
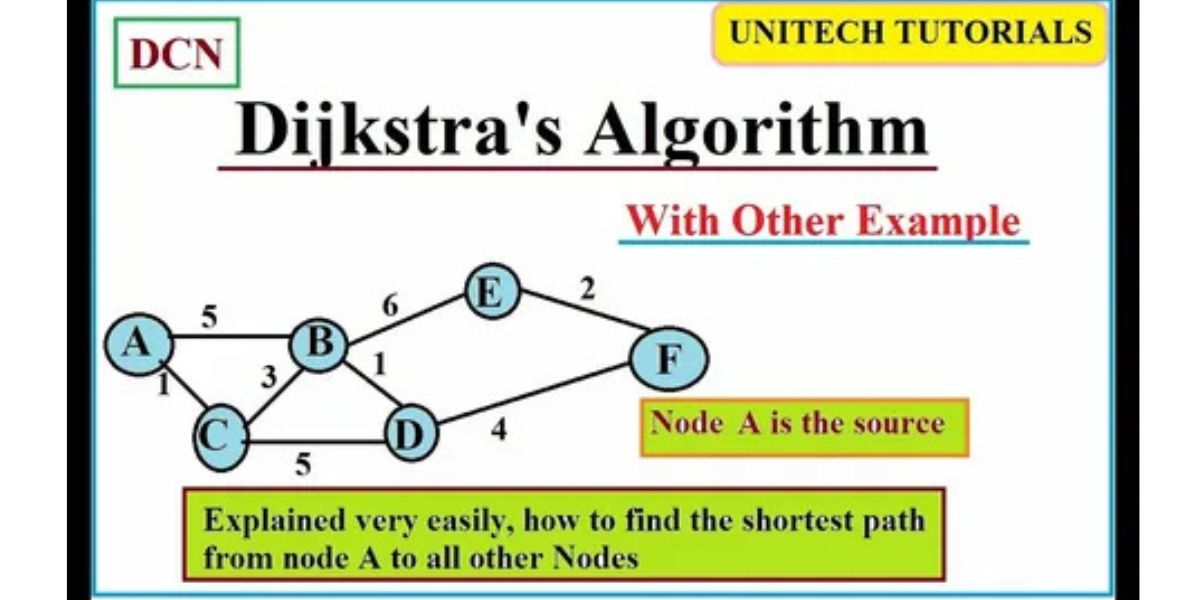
Wichtig ist die Bedingung: keine negativen Kanten. Wenn es negative Gewichte gäbe, könnte man theoretisch „Kosten“ durch einen Umweg senken – und Dijkstra ist dafür nicht gebaut. In solchen Fällen braucht man andere Algorithmen (z. B. Bellman-Ford). Diese Grenze ist entscheidend, weil sie zeigt: Ein algorithm ist immer an Modellannahmen gebunden.
Dijkstra Algorithm Schritt-für-Schritt, ohne Mathematikballast
Dijkstra funktioniert in einem einfachen Rhythmus: Du startest beim Startknoten mit Distanz 0, alle anderen sind zunächst „unendlich“. Dann wählst du immer den Knoten aus, der aktuell die kleinste bekannte Distanz hat und noch nicht „final“ ist. Von dort aus versuchst du, alle Nachbarn zu verbessern: Wenn der Weg über diesen Knoten günstiger ist, aktualisierst du deren Distanz. Sobald ein Knoten „final“ ist, bleibt seine kürzeste Distanz sicher richtig – das ist die zentrale Invariante, die den Algorithmus zuverlässig macht.
Wenn du das einmal verstanden hast, siehst du den dijkstra algorithm überall: Paket-Routing, Social-Network-Graphen, Spiel-Pathfinding, Supply-Chain-Optimierung. Und du verstehst sofort, warum die Priority Queue so wichtig ist: Sie sorgt dafür, dass das „wähle den kleinsten Distanzknoten“-Prinzip effizient bleibt, statt jedes Mal die ganze Menge zu durchsuchen.
Ist Dijkstra ein Greedy Algorithm? Ja – und das ist der spannende Punkt
Ja, Dijkstra wird häufig als greedy algorithm betrachtet, weil er in jedem Schritt den aktuell nächstliegenden Knoten „greedy“ auswählt. Der Unterschied zu „Greedy scheitert oft“ ist hier die Struktur: Bei nicht-negativen Kanten garantiert die Graph-Eigenschaft, dass diese lokale Wahl sicher ist und nicht später „entwertet“ werden kann. Genau das ist eine elegante Lektion: Greedy ist nicht gut oder schlecht – er ist gut, wenn die Problemstruktur Greedy erlaubt.
Das ist ein extrem wichtiger Denkrahmen für algorithmische Entscheidungen im Job: Statt zu fragen „Ist Greedy erlaubt?“, fragst du „Hat mein Problem die Eigenschaft, dass frühe lokale Entscheidungen später nicht kaputtgehen?“ Wenn ja, bekommst du schnelle, saubere Lösungen. Wenn nein, brauchst du eine andere Klasse von Methoden.
Algorithmische Denkweise im Alltag: Drei Szenarien, die du sofort erkennst
Stell dir vor, du planst eine Lieferroute mit mehreren Stopps. Wenn du immer den nächstgelegenen nächsten Stop nimmst, nutzt du eine greedy Strategie – das kann gut sein, aber ist nicht garantiert optimal. Wenn du dagegen ein Straßennetz als Graph modellierst und die kürzeste Verbindung zwischen zwei Punkten brauchst, ist Dijkstra oft das robuste Werkzeug. Schon diese Unterscheidung zeigt, wie ein algorithm aus einer Alltagssituation eine klare Struktur macht.
Ein anderes Szenario ist Scheduling: Du willst Meetings so legen, dass du maximal viele schaffst. Das ist ein klassisches Greedy-Problem, wenn du die richtigen Regeln wählst. Und ein drittes ist Suche: Du willst in einer großen Datenmenge etwas finden. Dann sind Datenstrukturen (Hash, Baum) und Suchalgorithmen entscheidend. Algorithmik ist also nicht „nur Informatik“, sondern eine Art, Entscheidungen systematisch zu modellieren.
Die häufigsten Fehler, wenn Leute „Algorithm“ lernen
Viele lernen algorithm wie Vokabeln: „Dijkstra ist kürzester Weg, Greedy ist lokal best“. Das reicht nicht. Der eigentliche Skill ist Transfer: Wann ist mein Problem ein Graph? Welche Annahmen gelten? Welche Eingaben sind groß, welche klein? Welche Fehlerfälle sind möglich? Wer diesen Transfer beherrscht, kann neue Algorithmen schnell aufnehmen, weil er nicht bei Namen hängen bleibt, sondern bei Strukturen.

Ein zweiter Fehler ist, Effizienz zu früh oder zu spät zu beachten. Anfänger optimieren, bevor etwas korrekt läuft. Profis bauen manchmal korrekt, aber vergessen Skalierung, bis es brennt. Die professionelle Mitte ist: erst korrekt, dann messen, dann die Engpässe verbessern. Das ist auch algorithmisches Denken – nicht nur Code-Schreiben.
Vergleichstabelle: Algorithm-Typen und wann du sie wählst
| Algorithm-Typ | Kernidee | Typische Probleme | Stärken | Grenzen |
|---|---|---|---|---|
| Greedy Algorithm | lokal beste Wahl pro Schritt | Intervallplanung, MST-Varianten, Teile von Graph-Problemen | simpel, schnell, oft elegant | nicht immer optimal |
| Dijkstra Algorithm | kürzeste Wege bei nicht-negativen Gewichten | Navigation, Routing, Netzwerk-Analyse | korrekt, robust, breit einsetzbar | keine negativen Kanten |
| Divide & Conquer | Problem teilen und zusammenführen | Sortieren, Suche, geometrische Probleme | oft gute Komplexität | Rekursion/Overhead |
| Dynamic Programming | Teilprobleme speichern | Knapsack, Sequenzen, Optimierung | optimale Lösungen möglich | Speicher/Komplexität |
| Heuristik/Approximation | „gut genug“ statt perfekt | NP-schwere Probleme | schnell, praktikabel | keine Garantien (oder nur Grenzen) |
Diese Tabelle ist der schnelle Kompass: Wenn du ein neues Problem siehst, kannst du in Minuten eine plausible Algorithmusklasse wählen, statt im Nebel zu starten. Genau das ist der Unterschied zwischen „ich kenne Begriffe“ und „ich kann Algorithmen einsetzen“.
Ein Zitat, das Algorithmik auf den Punkt bringt
„A good algorithm is like a good recipe: clear steps, repeatable results, and predictable outcomes.“ Dieses Bild ist deshalb so stark, weil es die Brücke baut zwischen what is an algorithm und professioneller Engineering-Praxis. Rezepte sind nicht „Magie“ – sie sind strukturierte Prozesse, die du testen, anpassen und verbessern kannst. Genauso ist es mit einem algorithm.
Der Mehrwert des Zitats ist nicht Romantik, sondern Verantwortung: Wenn dein Ergebnis schlecht ist, liegt es entweder am Rezept (Algorithmus), an den Zutaten (Daten/Eingaben) oder am Kochen (Implementierung). Diese Trennung macht Fehlersuche plötzlich kontrollierbar und ist ein echtes Profi-Mindset.
Fazit
Ein algorithm ist eine klare, endliche Schrittfolge zur Problemlösung. Wer what is an algorithm wirklich verstanden hat, erkennt Problemstrukturen schneller, trifft bessere Methodenentscheidungen und kann Technik besser beurteilen – von Navigation bis Social Media. Der greedy algorithm zeigt, wie lokale Entscheidungen unter den richtigen Bedingungen global optimal sein können, und der dijkstra algorithm ist ein Paradebeispiel dafür, wie Greedy in Graphen mathematisch zuverlässig wird, solange die Modellannahme (keine negativen Kanten) gilt.
Wenn du Algorithmen langfristig lernen willst, lerne nicht Namen – lerne Muster: Eingaben, Ziele, Annahmen, Komplexität, Grenzen. Dann wird Algorithmik nicht härter, sondern klarer. Und du wirst merken: Sobald du die Denkweise verinnerlicht hast, wirkt der Begriff algorithm nicht mehr wie ein Buzzword, sondern wie ein Werkzeugkasten.
FAQ
What is an algorithm in simple words?
Ein algorithm ist eine klare Abfolge von Schritten, die aus Eingaben ein Ergebnis erzeugt und dabei zuverlässig endet.
Is Dijkstra algorithm a greedy algorithm?
Ja: Der dijkstra algorithm nutzt eine greedy Auswahl des aktuell nächstliegenden Knotens, und diese lokale Wahl ist bei nicht-negativen Kanten sicher optimal.
When should I use a greedy algorithm?
Einen greedy algorithm nutzt du, wenn die Problemstruktur garantiert, dass lokale beste Entscheidungen zu einer global optimalen Lösung führen oder wenn „gut genug“ schnell zählt.
Why can’t Dijkstra handle negative edges?
Weil der dijkstra algorithm davon ausgeht, dass eine einmal „finale“ Distanz nicht später durch einen Umweg verbessert werden kann – negative Kanten würden diese
Is an algorithm the same as code?
Nein: Ein algorithm ist die Idee bzw. Methode; Code ist die konkrete Implementierung. Ein Algorithmus kann in vielen Sprachen umgesetzt werden.
What’s the fastest way to get better at algorithms?
Lerne Problemtypen (Graph, Scheduling, Optimierung) und übe, aus einer Aufgabe zuerst ein Modell zu machen; dann werden algorithm-Entscheidungen deutlich einfacher.



